


Introducing test data without limits

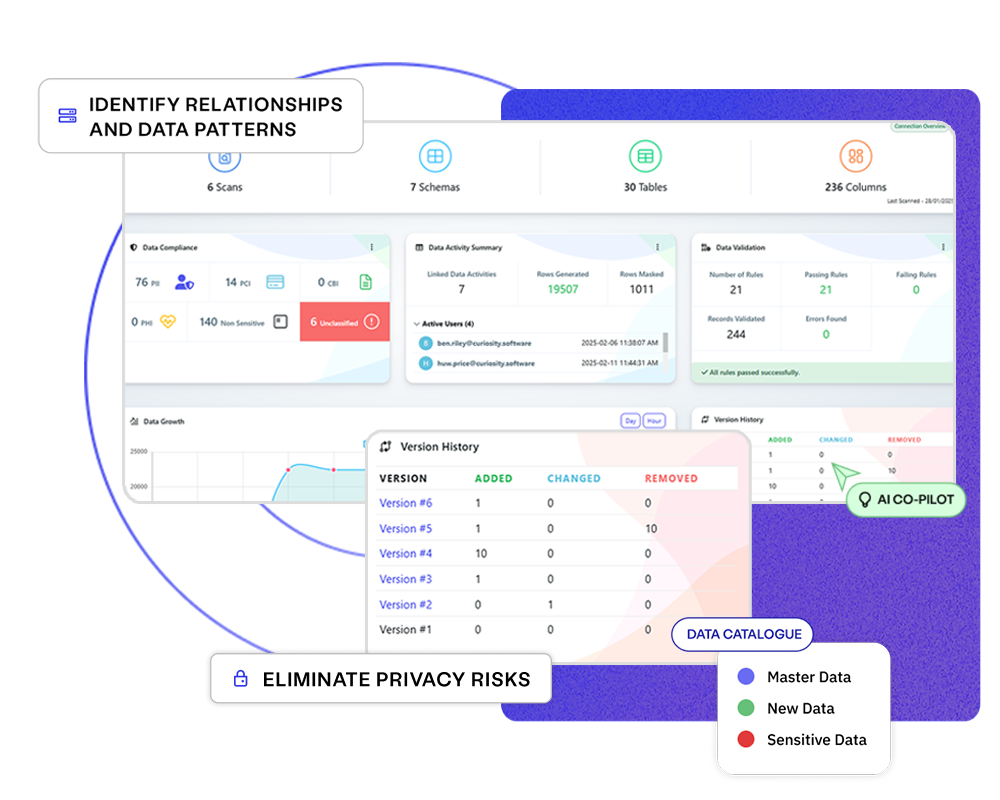
Build data understanding
Build a complete picture of your data landscape, bringing thousands of data sources into a single view, fostering effective test data management strategies.

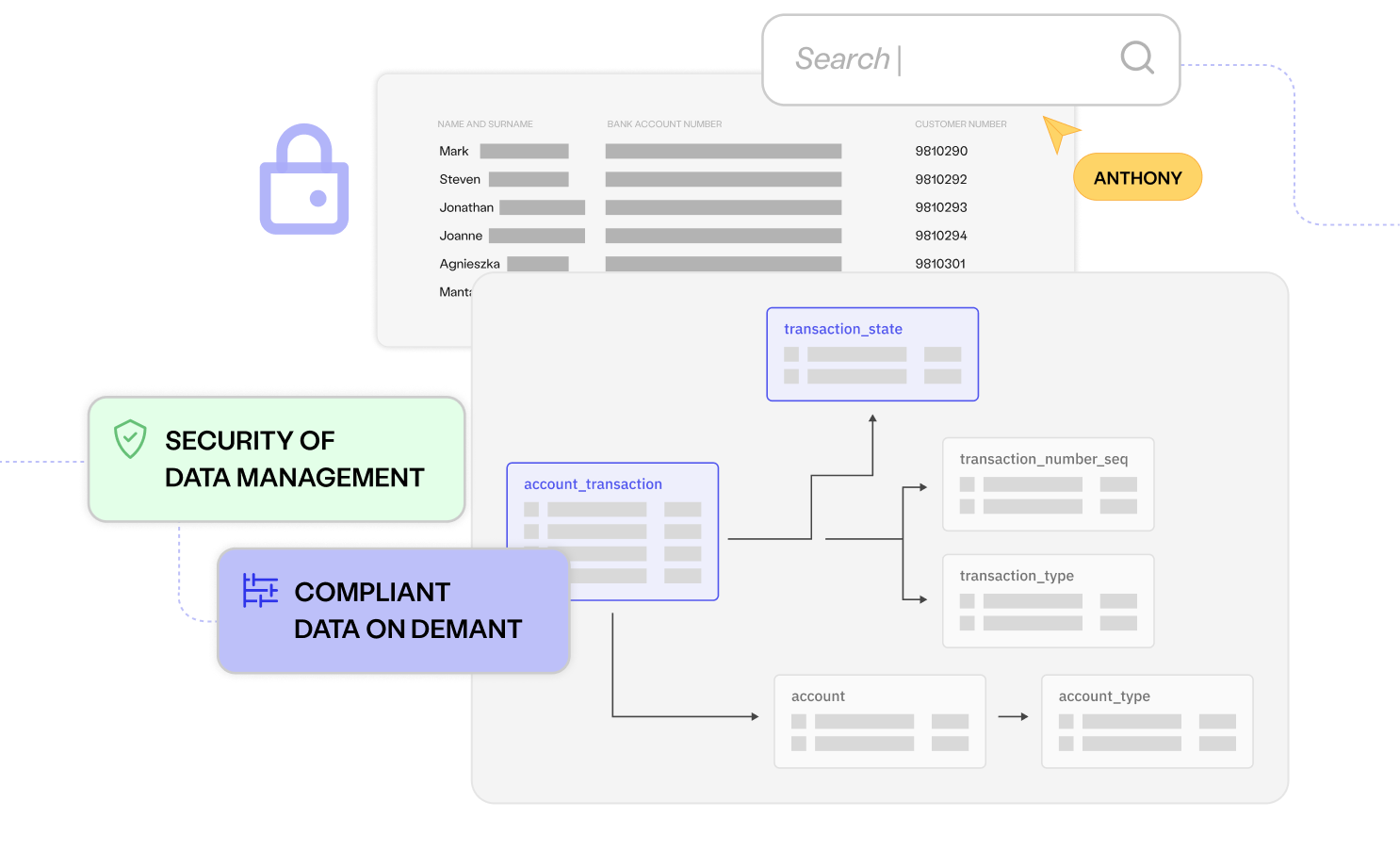
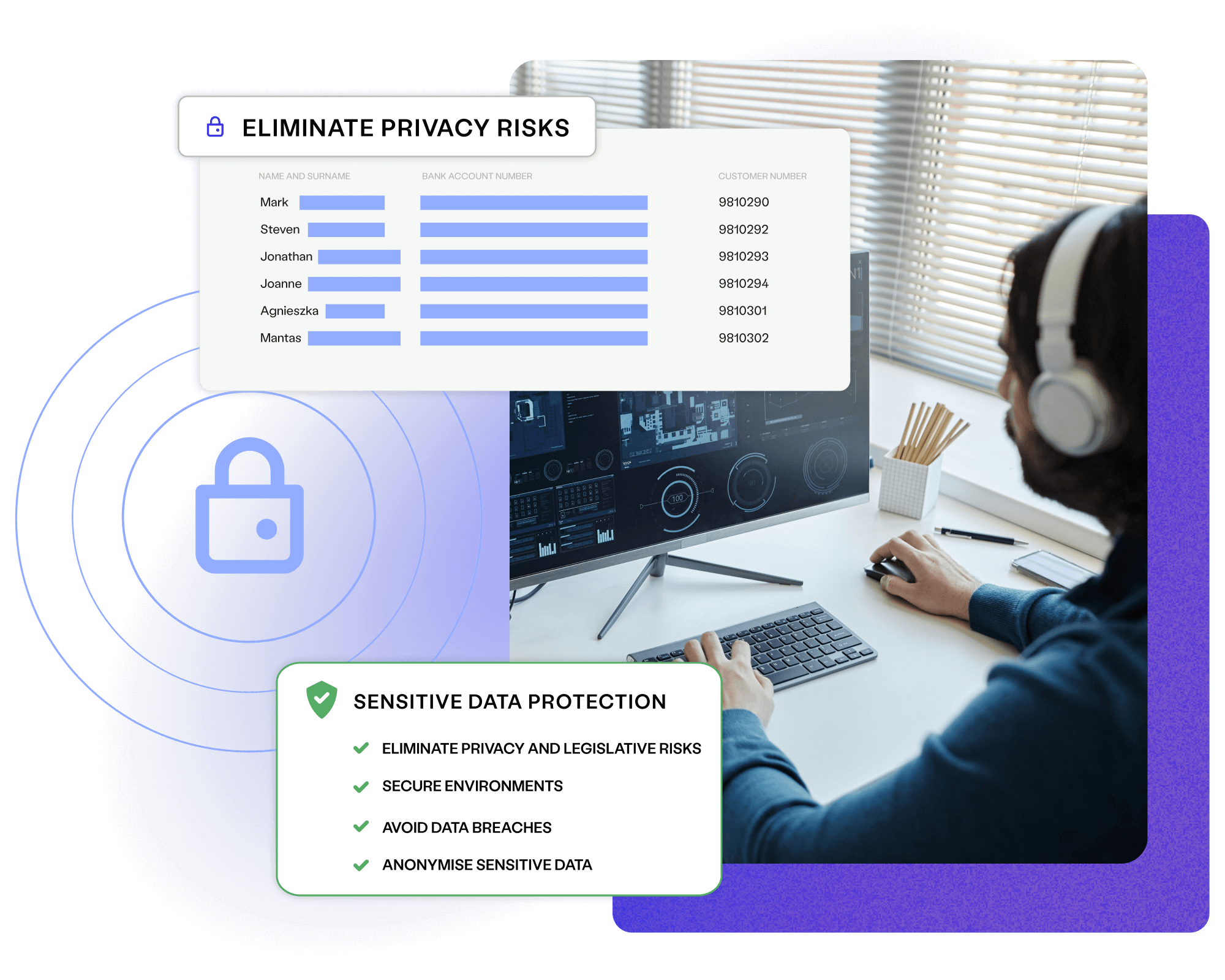
Avoid compliance risks
Take advantage of advanced masking and data generation capabilities to avoid the spread of PII, mitigating the risk of costly data breaches and fines.

Ensure AI readiness
Deliver vast, high-quality, and diverse datasets that can support AI initiatives, and help your organisation confidently fuel AI training and validation.

A proactive approach
Move from reactive slow test data delivery, to advanced, AI powered insights, actions, and delivery, while removing clashes and constraints.
How world-leading enterprises manage data
Discover smarter test data management
Gain a deep understanding of your data, intelligently execute on actionable insights, and intuitively monitor your application landscape with our end-to-end test data platform, powered by AI.
Data discovery Learn more
Build a complete picture of your data landscape to help you achieve the new standard of test data management with AI-powered discovery and insights.
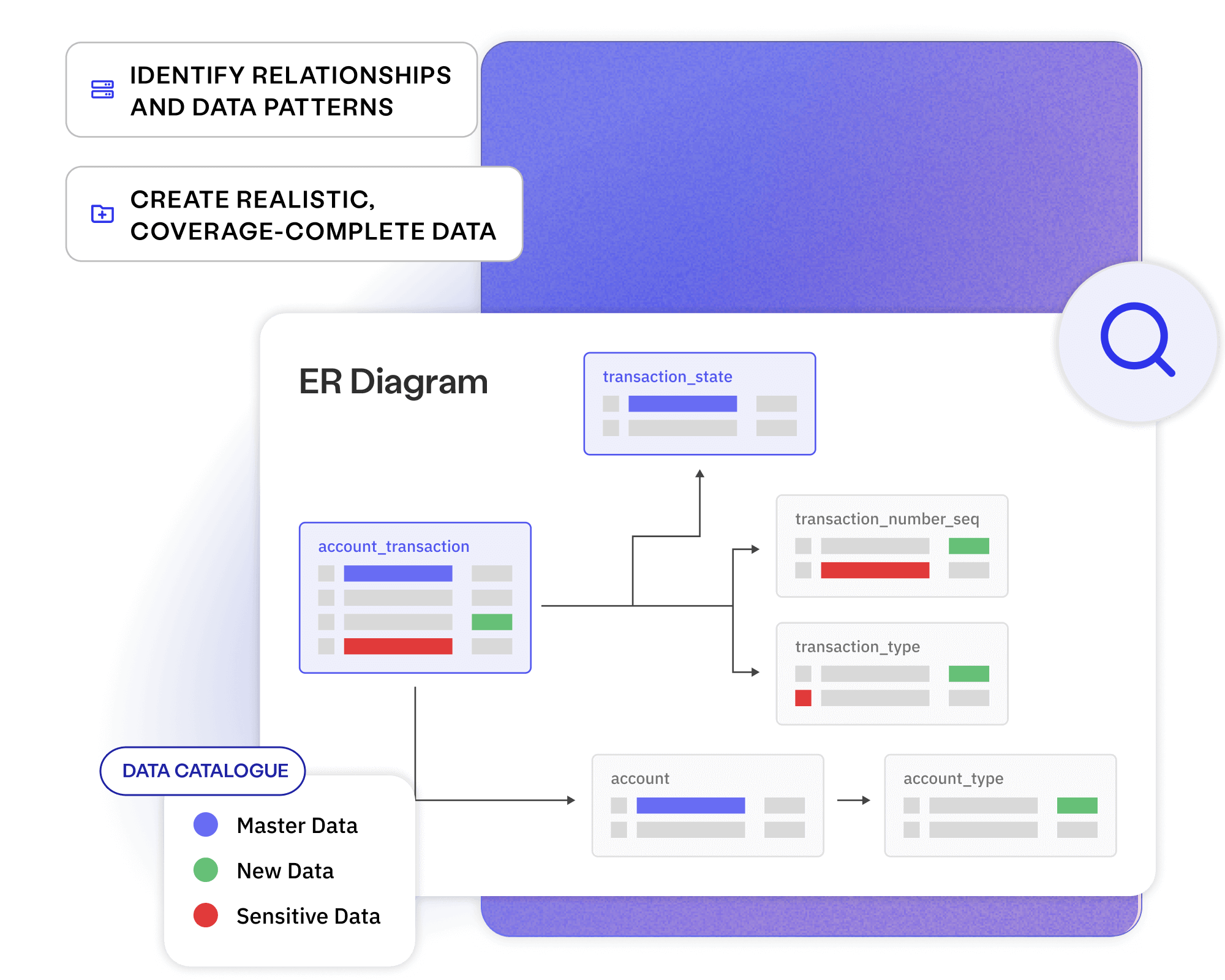
Data modelling Learn more
Design the data you need using visual models, and generate synthetic data with precision, diversity, and comprehensive coverage on demand.
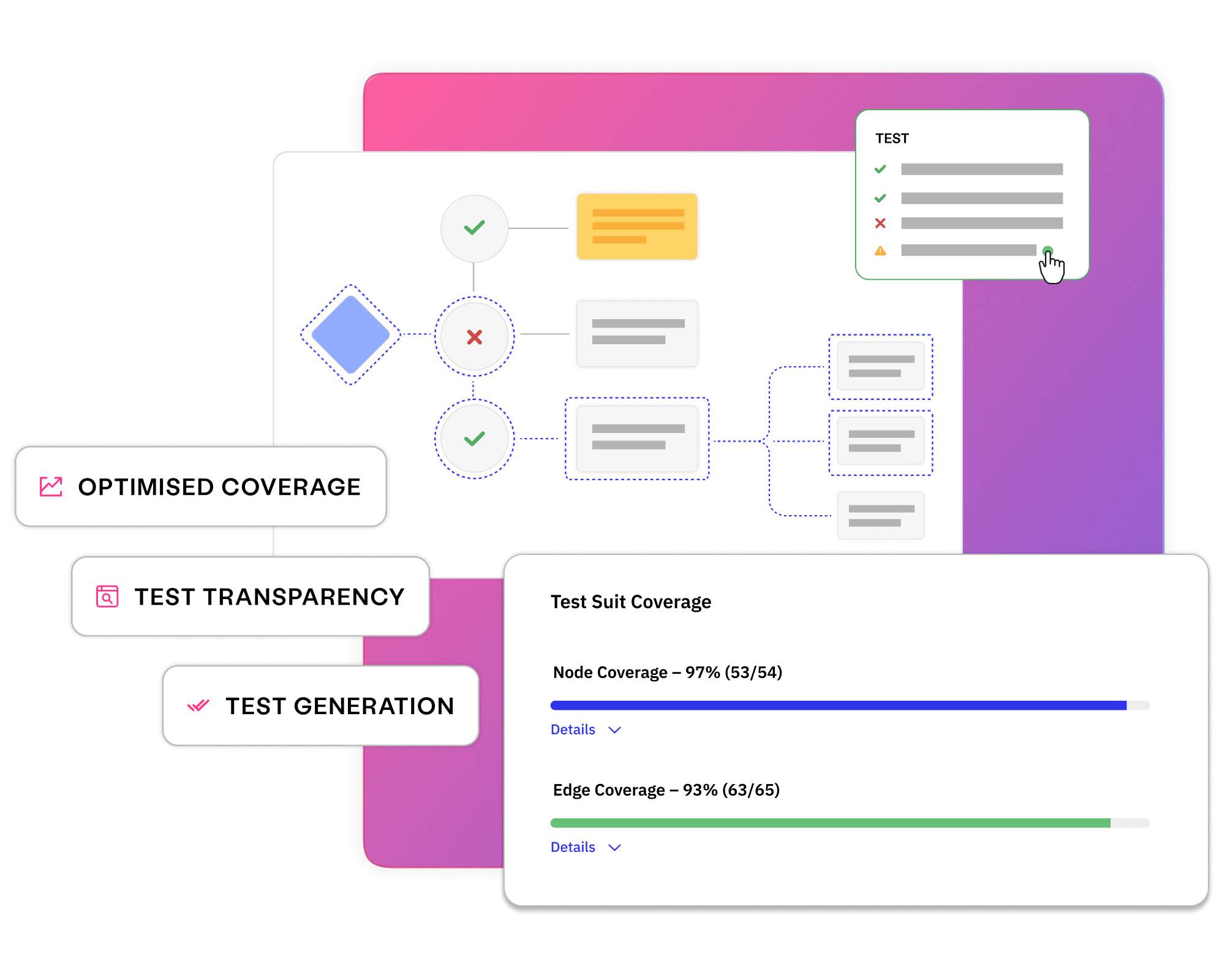
Data monitoring Learn more
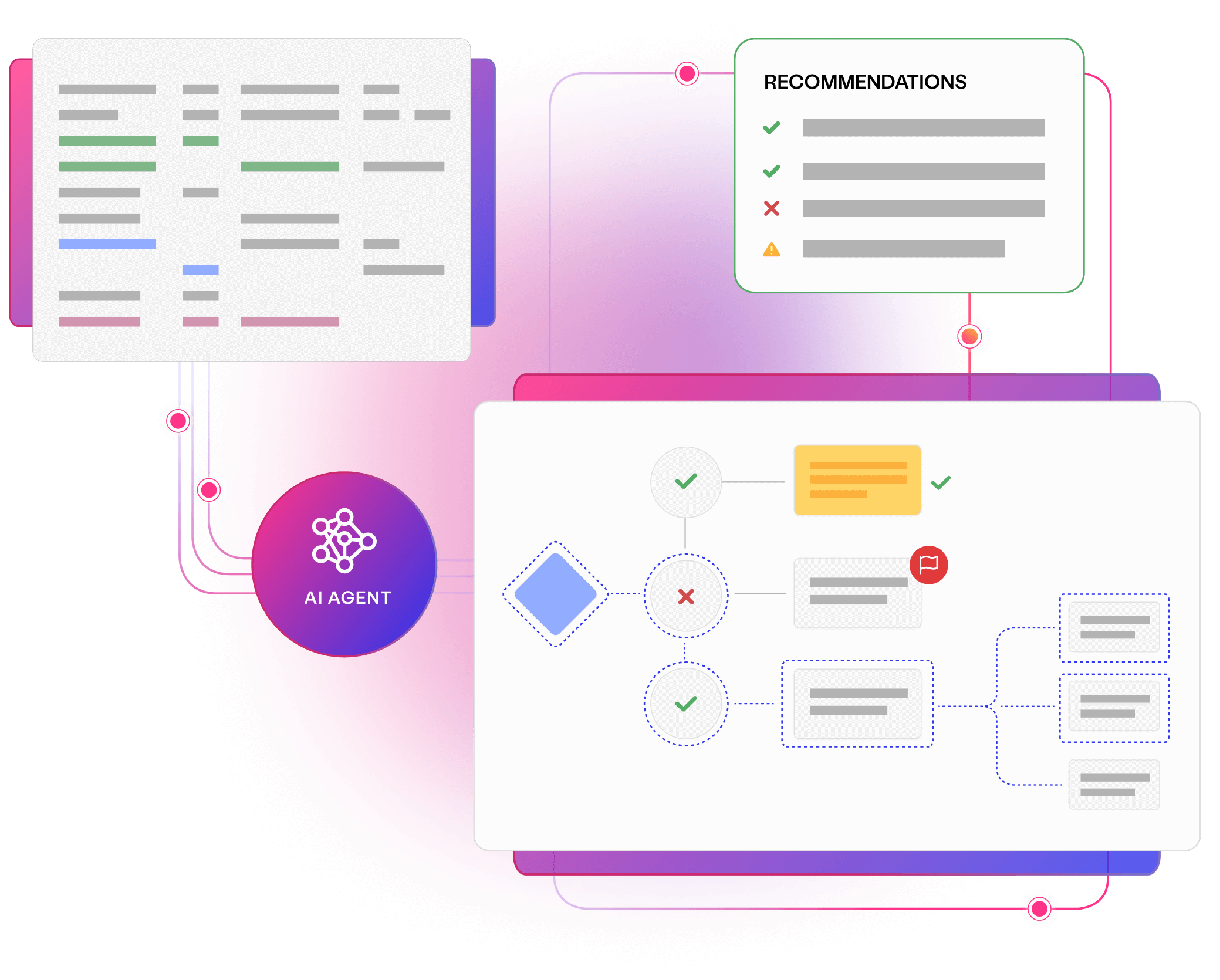
Leverage AI-driven insights to gain an accurate understanding of your current test data landscape and intuitively optimise processes, resources and data for future project needs.
AI-accelerated teams Learn more
Provide the domain expertise and specialist feedback your teams need. AI assistants pay off technical debt, provide on demand clarity, and augment your application landscape.
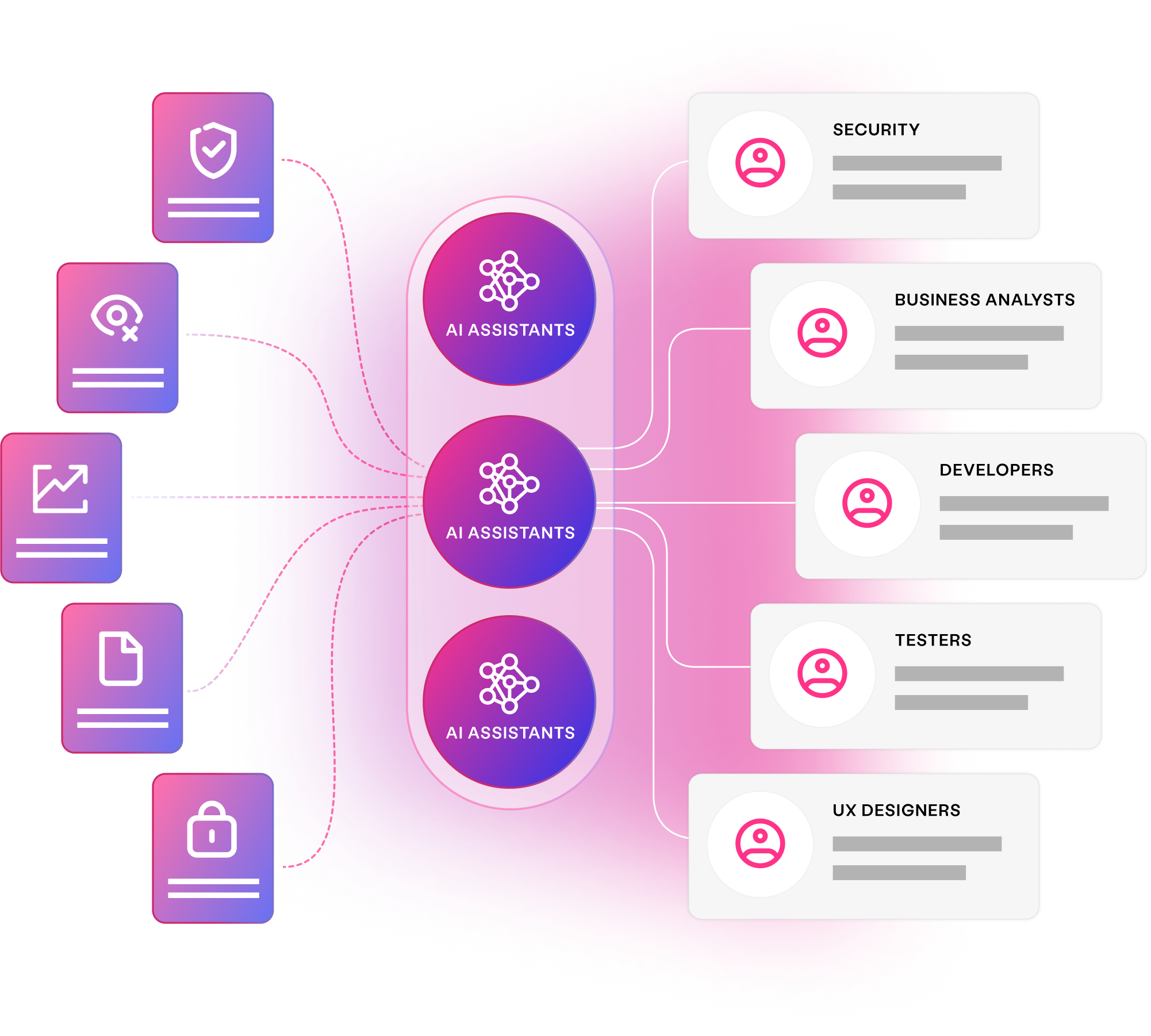
AI-accelerated data Learn more
Transform your data management with self-driving capabilities. Seamlessly deliver the right data, to the right teams, at the right time, across your entire enterprise.
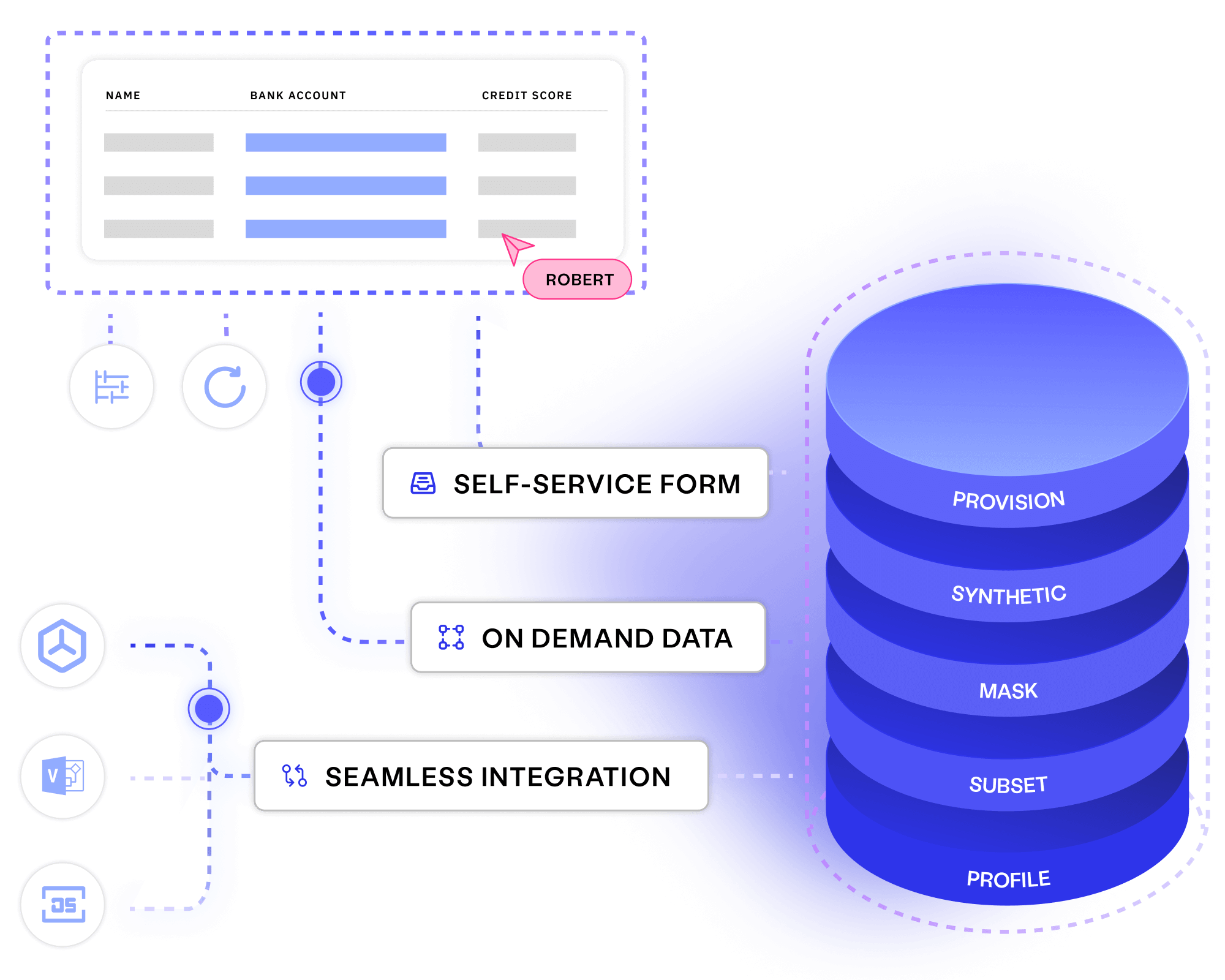
Data provisioning Learn more
Stop wasting delivery time finding, making and waiting for test data. Provision data using self-service forms, seamless integrations, and an automated test data toolkit.
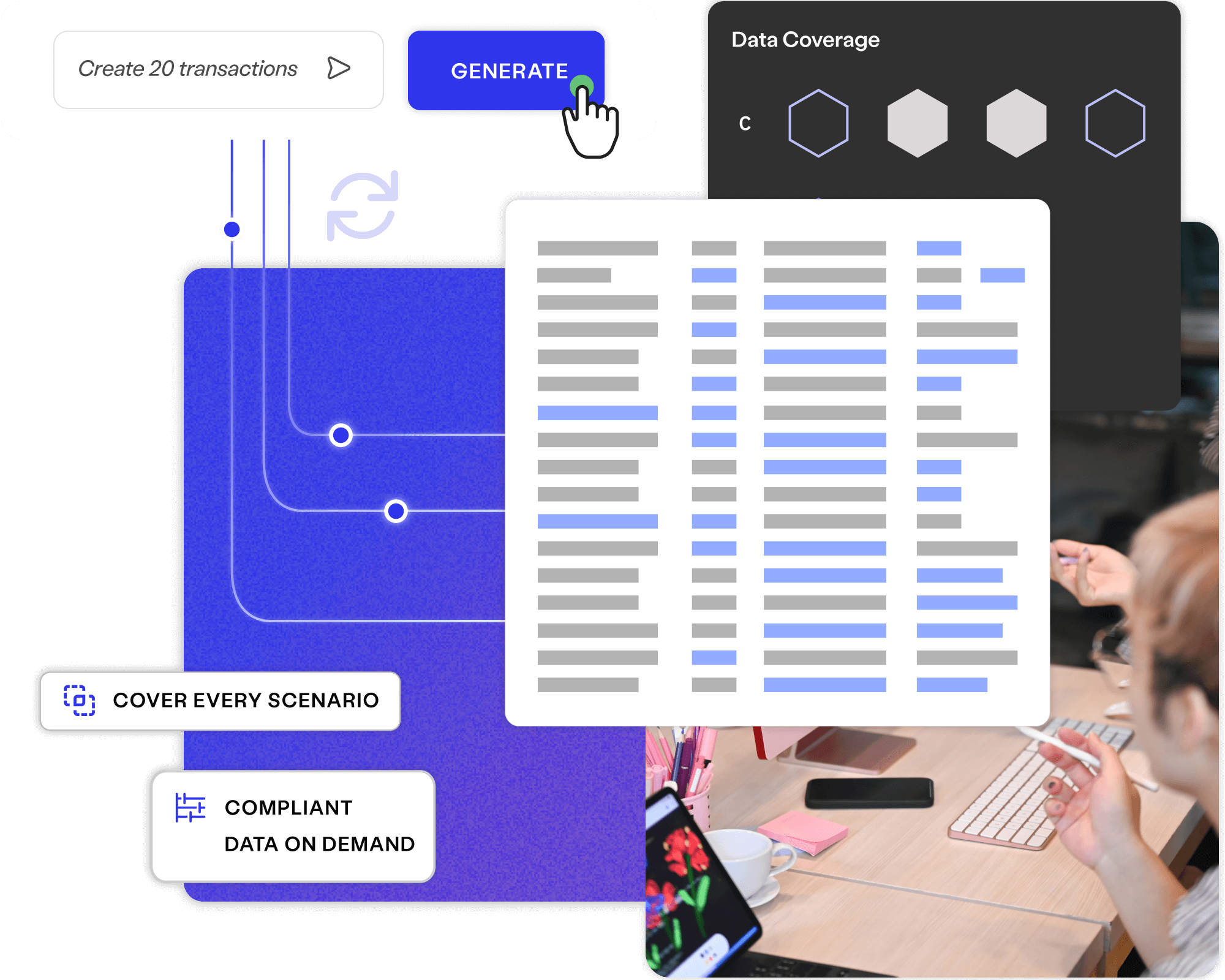
Synthetic data generation Learn more
Create fictitious data to cover every user story, test case and business requirement, available on demand to your entire delivery ecosystem.
Data masking Learn more
Automatically identify and anonymise sensitive data before it’s provisioned to less-secure environments. Avoid data breaches and ensure regulatory compliance.

The enterprise test data tool of choice
Across industries, some of the world’s largest enterprises use Curiosity's platform to deliver rich and compliant data on demand.
On-demand test data generation
- 5-day provisioning reduced to self-service
- Optimal quantities and variety of data on demand
- Data ranging from DB2 mainframe to BigQuery
Manually finding and making data adds up to one of the most resource-intensive, time-consuming tasks in testing and development. Automating provisioning can make the difference when striving to hit release deadlines and stay on budget.
Senior Test Data Engineer
On-demand, synthetic data warehouses
- Data generation for an AI-driven platform
- 50% more test data than all client data combined
- 18 test databases drive parallel development
AI is making system data more complex than ever. Developing AI-driven, AI-built systems requires diverse data that reflects intricate relationships, trends and hierarchies. Model-based data generation is perfect for overcoming this complexity.

Principal Test Data Engineer
AI-assisted requirements modelling
- 25% forecast reduction in bugs hitting code
- 8-20x fewer tests, generated with optimal coverage
- 30% forecast reduction in overall test design time
Using generative AI to visualise complex requirements provides the clarity developers need to build quality systems. The same models then generate optimal tests, testing continuously and paying off technical debt in requirements, tests and code.

Chief Technology Officer
Self-service test data
- $2M saved in year 1 provisioning costs
- 400 users run 1,000 provisioning jobs per week
- 50 weeks’ of labour time saved every week
Testers and developers can spend 20-50% of their time on data-related activities. Accurately and automatically provisioning test data is one of the biggest and fastest wins for enterprises seeking to deliver software faster and with better quality.

Test Data Engineering Lead
Launching a business critical platform
- 8x increase in test design speed
- Optimal test coverage for bug-free releases
- Synthetic test data removed privacy risks
Curiosity’s models ensured the reliability of complex connections between user types, so payments stay on target and private data remains secure … They identified minor and major bugs, so we could bring our product to market quickly—and guarantee our users a simple, worry-free experience.

John McElroy
President of Eljin Productions
Payment message generation
- 33x faster ISO 20022 message creation
- ½ day to regenerate test messages after a requirements change
- £300k saved in just one project
Payment platforms and complex banking systems are perfect for model-based data generation. We can break their intricate logic down into intuitive visual models, applying algorithms that create the smallest message set needed to cover diverse combinations.

Program Manager, ISO 20022
Continuous, collaborative test generation
- Generate new tests within minutes of code check-ins
- 85% of systems automated in 9 months
- 100% permutation coverage
Visual models break our system down in reusable chunks that generate the functional and visual tests we need. We can further assemble these reusable building blocks automatically as new courses are checked in, generating rigorous tests.

Greg Sypolt
VP of Quality Engineering
Automated API test generation
- Rigorous API testing within 2-week sprints
- 25x reduction in test volume vs exhaustive testing
- Optimal coverage, without under- or over-testing
Curiosity’s platform enabled rigorous in-sprint testing, while facilitating cutting-edge development practices like shift left API testing, fail-fast experimentation, and test-driven API design. It worked seamlessly alongside our teams and processes.

Johnny Pitt
Founder of ThinkDonate
Optimal requirements and tests
- 15x faster test creation vs scripting
- 10x faster test case design in Jira
- 50% overall increase in test coverage
Importing requirements to visual models not only generates rigorous test automation at speed; it also improves the requirements and pays off technical debt. This transparency and shared vision allows critical thinking upfront, while building quality throughout the delivery lifecycle.

Product Owner
Collaborative requirements & test generation
- AI imports and augments BPMN requirements
- Test suite generation in 45 minutes for new requirements
- Integration with written user stories and process maps
Miscommunications, silos, and a lack of transparency create bottlenecks throughout software delivery. AI can now diagram complex requirements and generate tests. This not only accelerates delivery and pays off technical debt; it also provides a collaborative vision that aligns every team.

VP of Application Delivery
Step towards data quality, privacy and compliance
Read a resource, or speak with an expert, to discover how you can transform your enterprise test data management.


Platform Ecosystem
Remove compliance risks and bottlenecks
Our platform integrates with your people, processes and tools, with over 250 data connectors covering databases, mainframes, files, messages and more.
View all integrations
Right data. Right place. Right time.
Rich, compliant data that is available across the entire enterprise


