Did you know that the Curiosity team have been creating test data solutions since 1995? We’ve seen, and led, several evolutions in test data “best practices” throughout this extensive history, driven by new technologies and techniques. This article is designed to help you navigate the complex test data management landscape that has emerged over the past ~30 years, deciding which solutions are best for your organisation’s people, process and tools.
We divide test data technologies into three categories. You’ll learn the history, benefits, and considerations associated with older legacy tools, newer “point solutions”, and emerging AI/ML solutions.
You’ll also learn how Curiosity have designed our tools and services to offer and exceed the benefits of each category, while avoiding potential drawbacks. This provides a fourth category of solution: An all-in-one, enterprise test data platform.

Curiosity have designed Enterprise Test Data to provide an all-in-one, enterprise test data platform.
Are you ready to integrate your test data processes into a complete platform? Talk to us to eradicate your test data bottlenecks, compliance risks and coverage gaps.
Why is the test data market so complex?
Test data is a large, multi-faceted discipline, and no two enterprises have the same requirements.
As new technologies emerge, they are furthermore often adopted alongside existing processes, which organisations struggle to modernise as they are mission-critical. Test data technologies at any one enterprise therefore tend to blend outdated methods with newer tools, often with limited integration and consistency.
This trend is reflected in the test data market, which offers older technologies alongside newer solutions and AI/ML tools. Let’s start by considering the older commercial test data technologies.
Legacy test data management (TDM) tooling
These are tools that first emerged in the 1990s and 2000s, with a focus on anonymising, subsetting and copying data. Some tools have since added data generation, with varying depths of functionality.
The history of legacy test data management (TDM) tooling
These legacy TDM tools emerged to meet the needs of a different world. They focussed on copying production data to non-production, often for the purpose of manual testing within a small number of environments.
The primary concerns were privacy and reducing storage costs, for which these tools offered anonymisation (“masking”) and subsetting. The emergence of commercial data generation technologies in the 2000s further enabled organisations to improve the coverage of their data, though few vendors offered these capabilities at the time.
Software delivery has transformed since the emergence of these “mask and copy” test data tools. Just think about the massive growth in data volume and variety, the new data types, “agile” software delivery methods, and the data requirements of automated testing. There are therefore, today, a range of challenges to consider at organisations who still rely on legacy test data tooling.
Considerations for legacy TDM tooling
1. Limited functionality and a lack of development
These tools have typically been acquired by large vendors, some of whom might have offloaded or cut funding to their development and services.
With limited R&D investment, there's no way a TDM tools can stay ahead of the functionality that enterprises need. Particular concerns include:
-
Support for new data types;
-
Performance and scalability to meet growing data needs;
-
Integrations with new technologies;
-
Reusability and self-service capabilities;
-
An overall lack of automation.
If you want to integrate these tools into your CI/CD pipeline, it typically further requires a lot of hand-cranking and technical work. However, the expert services required for such work are often in short supply.
2. A lack of expert support
The roll-out of legacy TDM tools can further be limited by a lack of expert implementation support, as well as a lack of expert coaching to change mindsets and practices. Some vendors have historically offloaded or lost expert test data personnel during acquisitions, or have handed customers off to third parties and local partners.
3. Unsustainable licensing and costly renewals
The legacy tools might also be expensive to license. They might have been sold as part of a portfolio or bundle of different tools. Organisations often then face paying more to license only the components they need, or licensing a range of technologies they won't use.
The difference in Enterprise Test Data
Migrating to Curiosity and Enterprise Test Data offers a range of advantages for organisations using legacy TDM tools. These include:
-
Sustainable licensing. With componentised subscriptions, you only pay for what you want and need.
-
Close support from test data specialists. You will work with veteran test data inventors, who partner with our customers to support a smooth migration and strong ROI.
-
New functionality and "future proofing". We continue to invest in R&D, to ensure that our tools and services stay ahead of enterprise needs.
-
An extensible, growing range of supported data types. From legacy to cutting-edge, Enterprise Test Data supports databases, files, messages and more.
-
Seamless self-service capabilities and CI/CD support. Parallel teams, automation frameworks and CI/CD pipelines self-serve the data they need, on demand.
-
A complete and growing set of test data activities. Enterprise Test Data provides tools for data provisioning, masking, subsetting and generation. However, these are integrated within an enterprise test data platform, offering a full and growing range of data activities. These include virtualisation, cloning, allocation, modelling, and more!
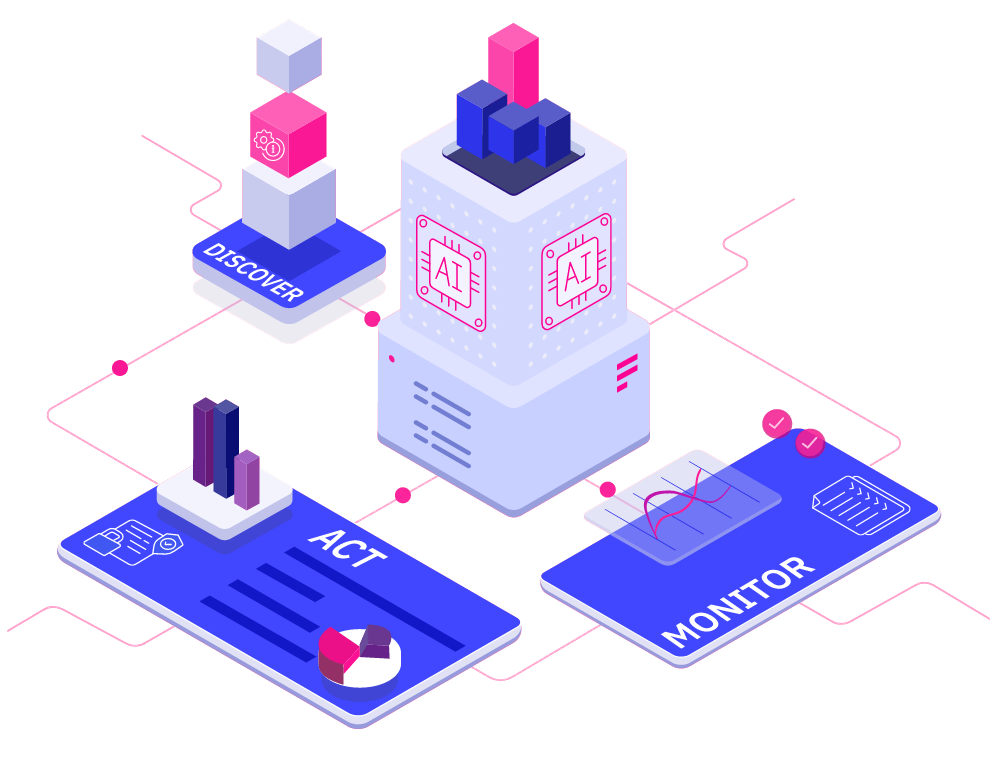
Enterprise Test Data from Curiosity provides a growing, integrated set of data activities, designed to meet the needs of a modern test data strategy.
Want to learn more about migrating from legacy TDM tools to Enterprise Test Data? Read our migration playbook for an example migration plan and ROI metrics.
Point solution start-ups
These are younger companies, typically start-ups, who have emerged over the last decade or so. They appear to offer solutions that combine 1-3 test data activities. Data masking seems to be the most common, often offered alongside either data virtualization or generation:

Several start-ups appear to offer a combination of masking, alongside generation or virtualisation.
These utilities each offer value within an enterprise test data strategy, However, there are several factors to consider when comparing test data “point solutions” to Curiosity’s complete and integrated test data platform.
1. Completeness of vision within test data
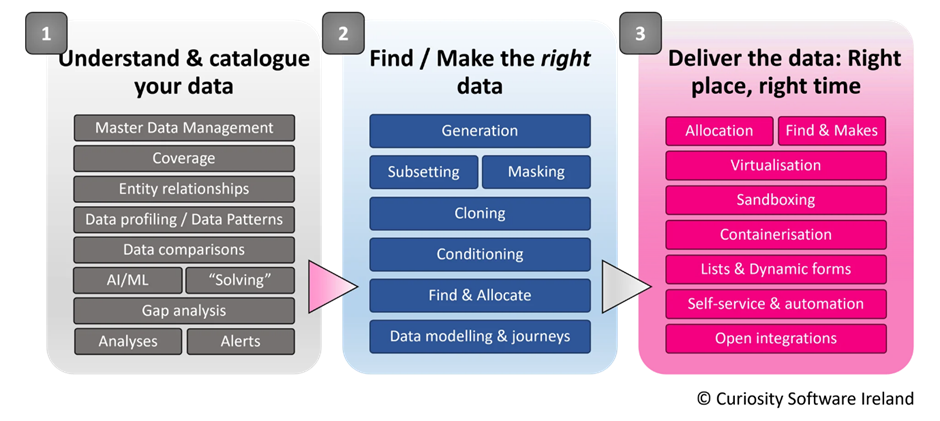
In addition to utilities for generation, masking and virtualisation, Enterprise Test Data offers an extensive range of integrated test data “activities”. These fulfil the array of activities and use cases that make up an effective test data strategy, allowing you to understand, find, make, mask, and allocate data. This range of these activities is indicated in the diagram above.

An extensive array of integrated, data activities are available in Enterprise Test Data’s intuitive web portal.
2. Total cost of ownership
Some point solutions might have costly licensing models for just one or two test data utilities. You also need to go through the additional effort of learning, integrating and maintaining several different tools to form a complete test data platform.
3. Completeness of vision beyond test data
Curiosity’s vision and technologies extends beyond test data, covering the whole delivery ecosystem. We offer integrated technologies that identify risks in software delivery, creating user stories, automated tests, and environments to mitigate them. We help deliver quality software at speed.
4. Experience and expertise
In the 28+ years that Curiosity’s team have been creating tools in the test data space, they’ve worked with a wide array of technologies, data sources and organisations. Curiosity offer test data specialists, who want to partner closely with your organisation, and whose experience extends decades earlier than the formation of recent test data start-ups.
“Generation” tools for ML training data
Most recently, data generation and masking tools have emerged from the world of ML training algorithms. Some vendors now appear to be positioning these tools for test data management.
The emergence of ML data generation tools
These tools specialise in creating data that reflects the statistical identity, or patterns, found in production data sets. They apply ML algorithms and multivariate analysis to understand these patterns, creating anonymised copies that retains the statistical identity of the original data.
This data can then be used to train ML algorithms, without the privacy risks associated with using production data.
Considerations of ML data generation tools
Overall, the focus of these tools appears to be privacy. They are, in practical terms, as valuable as data masking. They create production-like data, replacing sensitive values within original data sets.
While anonymisation is valuable for compliance, it does not alone address many of the pressing test data challenges associated with software delivery speed, quality and infrastructure costs. There are a therefore range of questions to consider when comparing ML data generation tools to an all-in-one enterprise test data platform:
1. Tools for understanding your data
Though multivariate analysis and ML algorithms help identify patterns in your data, these tools might not provide the full understanding needed to generate data that is referentially intact, coverage-rich and compliant.
Where tools don’t offer data profiling, you might still need to specify the location of sensitive data. This increases the risk of compliance violations rooted in human error.
Users might additionally need to specify or confirm data relationships, as required to produce referentially intact data sets. Yet, this deep understanding of data is often lacking at enterprises, who face vastly complex, heterogeneous technology stacks. Broken relationships in data in turn risks broken tests and bottlenecks.
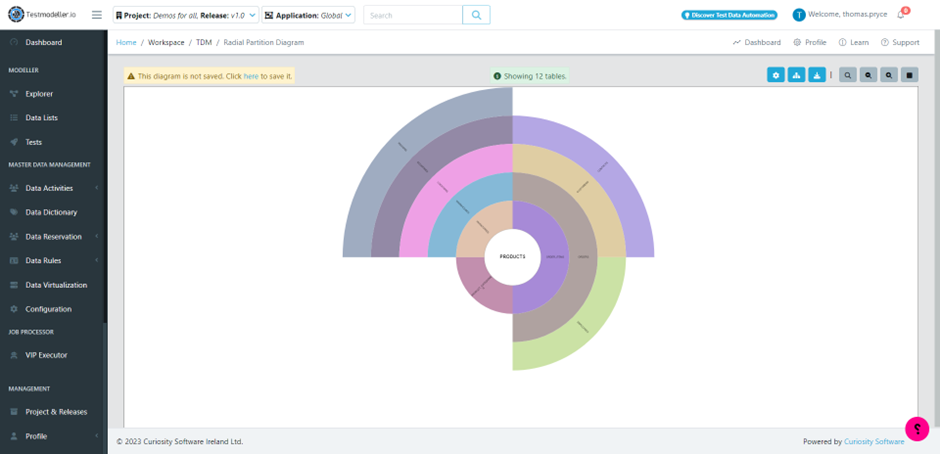
Enterprise Test Data provides a range of automated tools for understanding and visualising complex data.
To solve these challenges, Enterprise Test Data offers a range of techniques for understanding your data. In addition to ML pattern analysis, these include data profiling, comparisons, and validation. These tools reveal patterns, relationships and sensitive information in your data, creating a version-controlled “data dictionary”. These reusable data definitions then drive accurate data engineering.
2. Wide-reaching data generation capabilities
While Enterprise Test Data offers ML pattern and multivariate analysis for data generation, this is just one approach in a wider test data generation toolkit. Overall, 5 different synthetic data generation techniques meet the diverse data generation use cases found at enterprises today:
-
ML pattern analysis for generation: Machine Learning defines the patterns in your data, generating production-like data to match these distributions.
-
Data flow modelling: Visual flowcharts combine data generation functions and parameterizable jobs, designing coverage-optimised data that links across technologies.
-
“Complex” data explosion: Enterprise Test Data automatically identifies and combines every value in a data set, creating rich permutations for testing configurations, validations and more.
-
Data generation functions: Hundreds of combinable data generation functions generate fictitious data for columns and values, while fulfilling relationships uncovered in profiling.
-
DataGPT: Generative AI creates spreadsheet-like data. The data is diverse, realistic, and comprehensive, driving more effective testing and development.
3. Completeness of vision within test data
Some ML data generation tools offer capabilities in subsetting and masking. As discussed above, Enterprise Test Data offers these activities, but integrates them within a comprehensive, growing set of test data activities.
4. Self-service capabilities for finding and consuming data
Once production-like data is copied into non-production environments, testers and developers can still spend around 20-50% of their time on data-related activity. This includes searching for the combinations they need within large data sets, making missing values by hand, as well as time lost when useful data is constrained or has been edited in a shared environment.
Enterprise Test Data therefore provides a full spread of self-service data capabilities. Testers, developers, frameworks and CI/CD tools can self-provision the data they need, triggering reusable test data jobs on-the-fly. This includes self-service forms, alongside a range of integrations that pass parameters into Enterprise Test Data’s high-performance jobs engine.
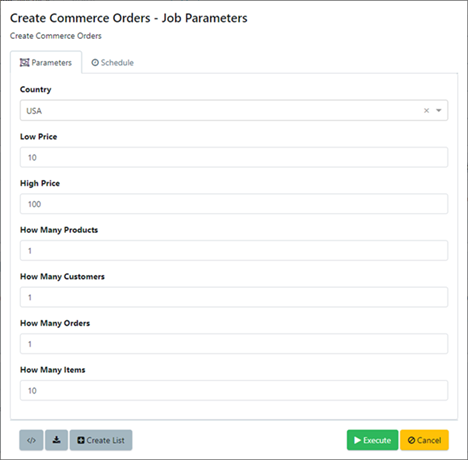
Self-service forms in Enterprise Test Data allow testers and developers to self-provision exactly the data they need.
5. Coupling of data, requirements and tests
Several test data technologies appear to focus on data creation in isolation from requirements and tests. Curiosity instead specialise in tightly pairing data to requirements and tests, allowing the creation and provisioning of data that is complete, up-to-date, and concise.
As discussed, our vision and tools extend to the whole software delivery ecosystem, spanning software ideation, design, development and testing.
6. Experience
Like the “point solutions” start-ups, many ML data generation tools have emerged in the past 5-10 years. Curiosity’s team have instead been creating data solutions since 1995, offering test data experts who have worked with an extensive range of technologies, data sources and organisations.
Time for a change?
Do you want (or need) to modernise your test data strategy? Is test data blocking you from meeting your enterprise’s goals for quality, compliance and delivery speed?
Curiosity partner closely with our customers to identify the best test data strategy for their specific needs, before integrating new test data technologies and modernising existing practices. Talk to us to start your journey to faster, better software delivery.
Disclaimer: The presentation of any technology and technique contained in this article is based on Curiosity’s research of material available publicly at the time of writing. The analysis represents interpretation of the available information and should not be considered definitive or comprehensive.