

Automated Solr data provisioning
Populate, mask, subset and generate Solr data on demand
Populate high volumes of rich Solr data into test environments on demand, rigorously testing fast-changing systems. Test Data Automation combines flexible masking, subsetting and generation with self-service provisioning, all integrated seamlessly into DevOps toolchains.

Rich Solr data, available on demand and in parallel
Test Data Automation provides a simple, automated and on demand approach to populating rich Solr data in QA environments, manipulating it on-the-fly to enable rigorous testing and test compliance at speed. High-speed, parallelized workflows move high-volume data from a range of sources to Solr and Docker containers in seconds and are available on demand from a self-service web portal. Parallel test and development teams can request the rich Solr data they need to ensure that systems delivery valuable insights, unconstrained by the delays associated with slow and manual data provisioning.
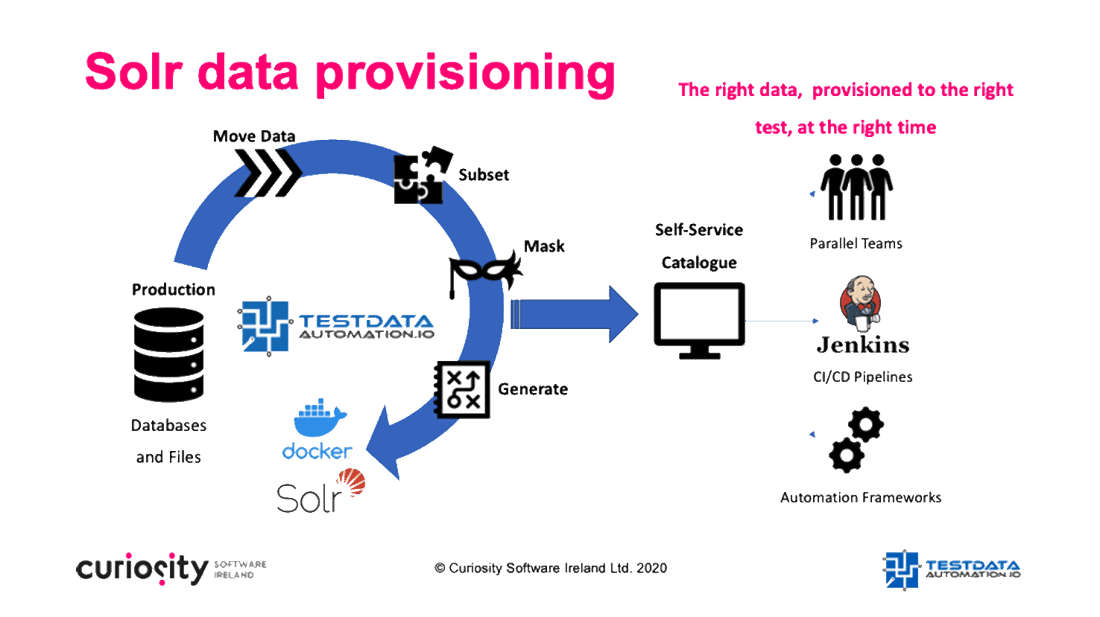
The rapid data loads weave in the flexible test data processes needed to ensure that QA is rigorous and compliant, testing business-critical systems without the risk of exposing sensitive data. Rapid and reliable data masking anonymizes data as its moved to Solr on demand, while “criteria” subsetting can be used to request exact data combinations needed to fulfil specific test scenarios. “Covered” subsets and seamlessly synthetic test data generation enhance the quality of data as it’s moved to Solr, including model-based data generation to ensure that tests execute every positive and negative data journey.
Configuring the utilities is as quick and simple as populating a fill-in-the-blanks spreadsheet and exposing the process to the on demand data portal, while data can be pushed to Docker containers, resolved dynamically during automated test execution, and triggered as part of CI/CD pipelines. The result? “Agile” test data available in parallel and on demand, with testing that matches the speed of your Solr searches.

Speak with an expert
Discover how Curiosity can help you automate your test data management!
