

Data Driven Test Automation for OpenText UFT
A Model-Based Approach
Automatically generate UFT data sheets that contain every distinct combination of data, for rigorous and robust data driven testing. Test Modeller finds, makes and prepares data “just in time” for OpenText (Micro Focus) UFT, providing accurate data for every test on demand.

Test Data Prevents Testing Speed and Rigour
Data-Driven test automation is only as good as the test data that feeds it. Rigorous testing requires a varied and realistic set of data, containing every combination of positive and negative values that needs to be tested. However, many of these vast combinations are missing in the copies of production data that are often provisioned slowly to testers. This repetitious, unwieldy data instead focuses almost exclusively on expected results, and cannot detect the majority of costly bugs first time round.
Test data also compromises testing speed, in addition to quality. A lack of automated test data allocation and re-usability forces testers to hunt repeatedly for the exact data combinations they need among the large production copies. They must create any missing values and combinations manually, inadvertently creating invalid data combinations. Automated tests then fail when there are no defects in the code, and bad data destabilizes automation frameworks. Competition for a limited number of data copies also creates delays among testers, while one automated test often consumes the data needed by another test.

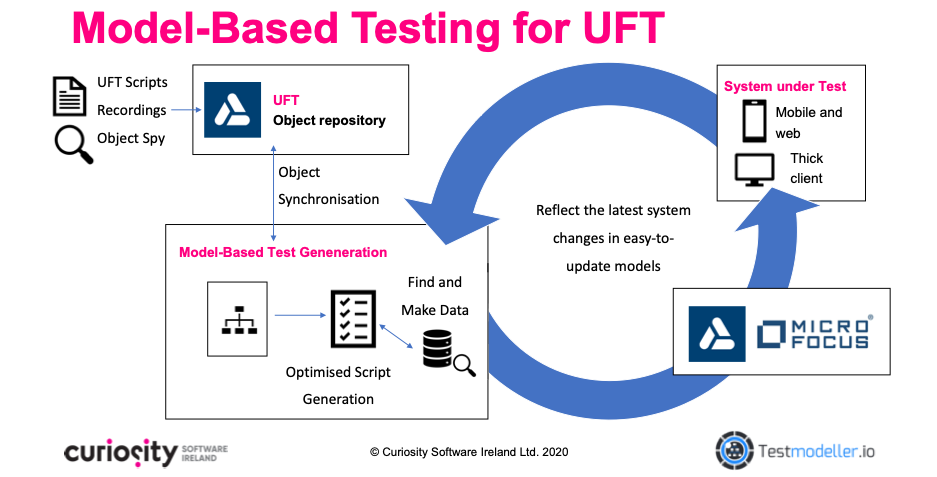
Model-Based Testing for OpenText UFT
Test Modeller eliminates bottlenecks created by test data, automatically preparing a set of data that is complete, executable, and available on demand. Complete test data is prepared “just in time” during test executing, ensuring that every UFT test comes equipped with valid and up-to-date data. This leverages a re-usable catalogue of test data processes, empowering testers to find, make, subset and clone data as a standard step in test automation. With Test Modeller, QA teams can rapidly create data sets with which to drive rigorous UFT testing, working rapidly and in parallel from on demand data.

On Demand Test Data for Every OpenText UFT Test
Watch this short demonstration of rigorous UI testing against a CRM system to see how:
-
Test Modeller automatically registers parameterised OpenText (Micro Focus) UFT scripts and corresponding data tables, enabling automated generation for existing frameworks.
-
Automated test generation algorithms generate a set of test data that “covers” every data combination needed for rapid and rigorous UFT testing.
-
A test data catalogue embeds re-usable TDM processes at the model level, finding and making up-to-date test data automatically as tests are generated.
-
The test data catalogue means that a TDM process only needs to be configured once, enabling testers to parameterise and re-use it in parallel from a simple form.
-
Automated data look-ups hunt for data for tests as they are generated, going directly into databases, or via APIs and front-end applications.
-
A full range of test data utilities prepares data automatically as a standard step in automated test execution, finding, subsetting and cloning data in batch.
-
Synthetic test data generation automatically creates any new data required, rapidly producing a set of data driven tests that hit every positive and negative combination.
-
“Just in time” test data preparation ensures that data is up-to-date and valid for each test, avoiding the delays created by automated test failures.
-
Assigning unique values to each and every test avoids the bottlenecks created when one test consumes data needed by another test.
-
Test data is validated and updated each time tests are generated and run, making sure that each test has valid and up-to-date data associated with it.
-
Multiple coverage profiles target testing on high-risk or critical data combinations, reducing the number of UFT tests without undermining testing quality.

Speak with an expert
Discover how Curiosity can help automate your test automation today!