



We've been getting an interesting question lately: “Why not use ChatGPT to create test data?” On the surface, it sounds like a cool idea. Just type in what kind of data you want and hit “Enter”! Magically, you've got a response packed with your generated data.
The linguistic capabilities of ChatGPT, developed by OpenAI, are undeniably impressive. The model can generate rich, diverse, and naturalistic language data, serving as a plentiful source of test inputs. In this blog, we seek to look at the effectiveness and drawbacks of using ChatGPT for data generation.
What is ChatGPT, and how does it work?
ChatGPT by OpenAI, along with other large language models (LLMs), have taken the world by storm. If you haven’t heard of it by now, you’ve probably been living under a rock for the past 9 months. The LLMs and Generative AI will drive efficiency in every industry. The New York Times outlined several fantastic ways that people are already leveraging these technologies.
ChatGPT is so good at formulating responses, that it’s sometimes hard to remember that it’s not a real human who you are chatting with. Few people using ChatGPT know its inner workings; simply, it is using neural networks which simulate the neurons in our brains.
Trained on huge datasets (at a rumoured cost of over $100 million), the ChatGPT generation method relies on a principle of randomness. While it provides varied content, this also injects a degree of unpredictability into ChatGPT’s output. Essentially, it “guesses” the next word in a sequence, based on a combination of learned patterns and probabilistic calculations.
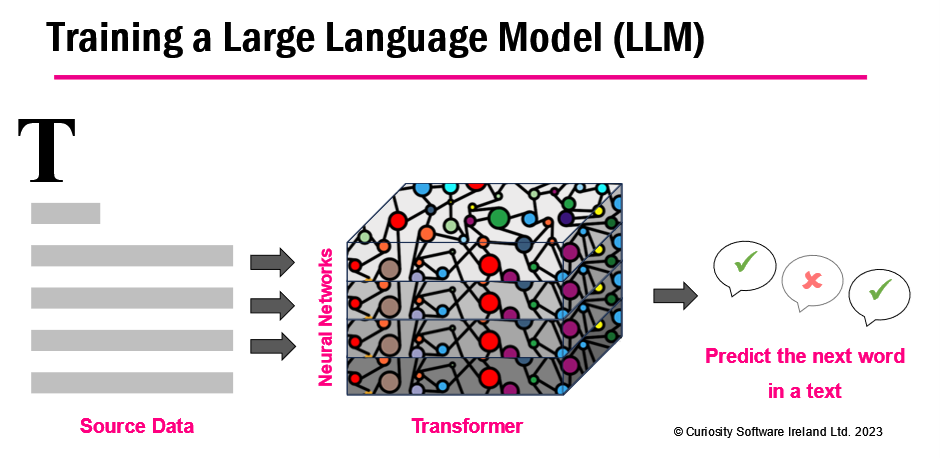
ChatGPT is trained to “guess” the next word in a sequence, introducing randomness and unpredictability.
If you are considering possible applications of ChatGPT, there is a critical aspect to understand: While ChatGPT is highly efficient at producing human-like text, it does not truly “understand” the content it generates in a way that human authors do.
ChatGPT does not possess a world model, knowledge about specifics, or any form of consciousness. It operates solely based on patterns it has recognized in the data it was trained on, which is largely internet text.
Although this vast range of information contributes to the model's ability to generate diverse text, it also means the model may reproduce biases present in the data it was trained on, presenting challenges for its use in certain scenarios.
The model also lacks knowledge of your organisational context and domain, as required to test effectively. Fed primarily on internet text, it has no way of “knowing” private information about your organisation’s systems, processes, rules, standards and implementations:
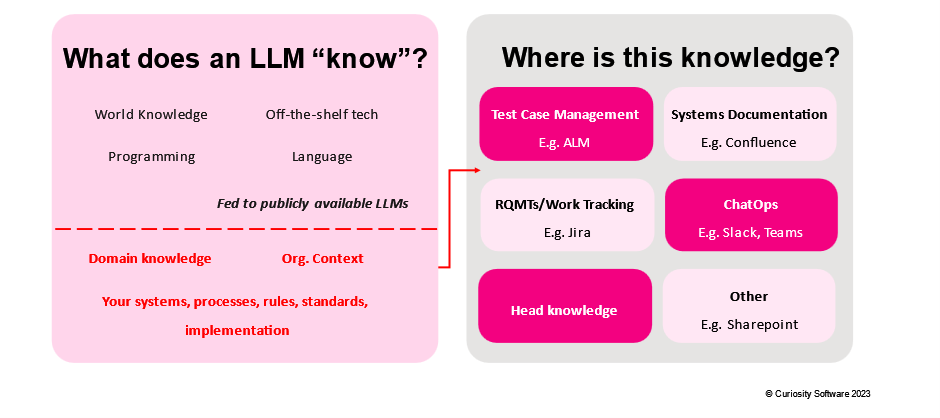
Foundational Large Language Models (LLMs) can reproduce biases in their training data, and have not been fed data relevant to “understanding” your organisation.
In the next sections, we will dive deeper into the randomness of ChatGPT's generation method and its implications, particularly regarding the concept of test data coverage.
The allure of ChatGPT for synthetic test data generation
Let’s look at some example prompts, and responses for generating data from ChatGPT. We’ll be using DataGPT, which is our wrapper around GPT4 for generating test data into a spreadsheet style format.
Prompt 1
"Given the business rules for credit card applications where to be approved a person must be over 18, have a credit score of at least 800, and have a good credit history, along with earning over $50,000 generate scenarios covering all possible outcomes including approval and rejection scenarios. Output the following columns, age, credit score, credit history, salary, application state.”
Response:
|
credit_score |
credit_history |
application_state |
salary |
age |
|
850 |
Good |
Approval |
60000 |
20 |
|
780 |
Fair |
Rejection |
40000 |
25 |
|
820 |
Good |
Approval |
70000 |
35 |
|
750 |
Fair |
Rejection |
45000 |
19 |
|
810 |
Good |
Approval |
55000 |
28 |
|
790 |
Fair |
Rejection |
65000 |
30 |
|
830 |
Good |
Approval |
52000 |
23 |
|
770 |
Fair |
Rejection |
48000 |
27 |
|
840 |
Good |
Approval |
60000 |
32 |
|
760 |
Fair |
Rejection |
42000 |
22 |
Prompt 2
"In the context of an online banking system where a user can only transfer an amount up to their current balance, generate scenarios that cover both successful transactions within the limit and unsuccessful transactions that exceed the balance. Output the following columns: sender balance, receiver balance, amount to send, transaction approved or rejected, new sender balancer, new receiver balance."
Response:
|
new_receiver_balance |
receiver_balance |
new_sender_balance |
amount_to_send |
sender_balance |
transaction_approved |
|
700 |
500 |
800 |
200 |
1000 |
approved |
|
4000 |
1000 |
2000 |
3000 |
5000 |
approved |
|
600 |
600 |
250 |
300 |
250 |
rejected |
|
900 |
400 |
1500 |
500 |
2000 |
approved |
|
2000 |
2000 |
800 |
1200 |
800 |
rejected |
|
28000 |
20000 |
2000 |
8000 |
10000 |
approved |
|
1500 |
1500 |
4000 |
500 |
4000 |
rejected |
|
110000 |
50000 |
90000 |
60000 |
150000 |
approved |
|
3000 |
3000 |
1200 |
1500 |
1200 |
rejected |
|
800 |
800 |
500 |
600 |
500 |
rejected |
Prompt 3
"Given the business rules for an e-commerce platform's product return policy, where a customer can return a product within 30 days of purchase provided it's in the original packaging, is not damaged, and comes with a receipt, and the customer is then issued a refund within 14 days of the return approval. However, if the product falls into the category of 'non-returnable goods' (like perishable items, personalized items, digital downloads, etc.), no return or refund is possible. Furthermore, if the customer misses the 30-day return window but is within 60 days from purchase, they can still return the product, but they will only receive store credit instead of a refund. Generate scenarios that cover all possible outcomes, including successful returns and refunds, rejected returns, issuance of store credit, and non-returnable goods. Output the following columns, Purchase Date, Product Category, Product Condition, Receipt Included, Return Approval Status, Refund Issuance Date, Store Credit Issuance Date"
Response:
|
Refund Issuance Date |
Purchase Date |
Product Condition |
Return Approval Status |
Product Category |
Receipt Included |
Store Credit Issuance Date |
|
2022-01-15 |
2022-01-01 |
New |
Approved |
Electronics |
Yes |
|
|
2022-02-01 |
Used |
Rejected |
Clothing |
No |
||
|
2022-03-01 |
New |
Rejected |
Perishable items |
Yes |
||
|
2022-04-01 |
New |
Rejected |
Digital Downloads |
Yes |
||
|
2022-05-15 |
2022-05-01 |
Used |
Approved |
Electronics |
Yes |
|
|
2022-06-15 |
2022-06-01 |
New |
Approved |
Clothing |
Yes |
|
|
2022-07-01 |
Used |
Rejected |
Perishable items |
Yes |
||
|
2022-08-01 |
Used |
Rejected |
Digital Downloads |
No |
||
|
2022-09-15 |
2022-09-01 |
New |
Approved |
Electronics |
Yes |
|
|
2022-10-01 |
Used |
Approved |
Clothing |
Yes |
2022-10-15 |
How can you ensure test data coverage?
On the surface, the ability to generate such diverse and varied data scenarios with just a few prompts appears incredibly empowering. It opens a realm of possibilities where large volumes of test data can be created quickly and without much manual effort. However, one crucial question remains: How do we ensure that the data generated covers all the rules we've identified?
This is where the concept of data coverage comes into play. Data coverage, in a testing context, refers to the amount of data variety that is covered in your test scenarios. It provides a measure of how comprehensively your testing includes different data scenarios, including edge cases, typical cases, and exceptions.
Ideally, testing wants high data coverage, meaning your tests include a wide variety of data scenarios. This ensures that your system can handle a broad range of inputs. Let’s take, for example, a coverage map, which is a visualisation technique, similar to a heatmap for viewing the distribution of available data.
In this example, for Prompt 3 above, we have mapped the Approved/Rejected status of different product categories. You’ll see a missing data scenario for Rejected Electronics:
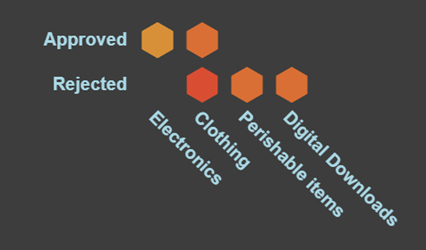
Likewise, if we look at the credit history vs. application state for Prompt 1 above, we’ll see more data gaps. The data outputted by ChatGPT has a low level of coverage. This is evidently lower as we look across more dimensions:

Here's the hitch: While models like ChatGPT are adept at generating data, they generate data randomly. The core method of operation for models like these is predicting the next word in a sequence based on probabilistic calculations. As discussed, this introduces a degree of unpredictability and randomness into the generated data.
While you might get varied data, there’s therefore no guarantee that the data will cover all possible scenarios defined by your business rules. High data diversity doesn't necessarily mean high data coverage.
Poor data coverage undermines our ability to test our systems rigorously. Afterall, we can only test as well as the data we have available to us. If we require a specific scenario (e.g. approving an applicant with an excellent credit history), then we can’t test it without first having the data created. This is often why production data is not a good data source to use for testing, and why most organisations will turn to synthetic data generation.
So, while using AI models like ChatGPT can be an attractive proposition for test data generation, it's crucial to consider the implications of its randomness.
Model-based testing: An alternative approach
In contrast to the randomness of test data generation with LLM-based AI models (like ChatGPT), there's a more systematic approach that can ensure comprehensive data coverage: Model-Based Testing (MBT) for synthetic data generation.
Modelling is an approach to software testing in which test cases are derived from a model that describes the functional aspects of the system under test. In the context of test data generation, the “model” would be a formal representation of business rules.
So, how does it work? You start by building a model of your system's behaviour, which includes the various business rules and the different scenarios that can occur based on these rules. This model serves as a blueprint for generating test cases. As the test cases are directly derived from the model, they inherently cover all the scenarios and business rules represented in the model.
The major advantage of MBT is that it allows for systematic coverage of your business rules. Since the model is a comprehensive representation of the system's behaviour, generating test cases from this model ensures that all possible scenarios defined by your business rules are included in your testing.
MBT additionally also supports automatic test generation. Using appropriate tools, you can automate the process of generating test cases from the model, which can save significant time and effort compared to manual test case design:
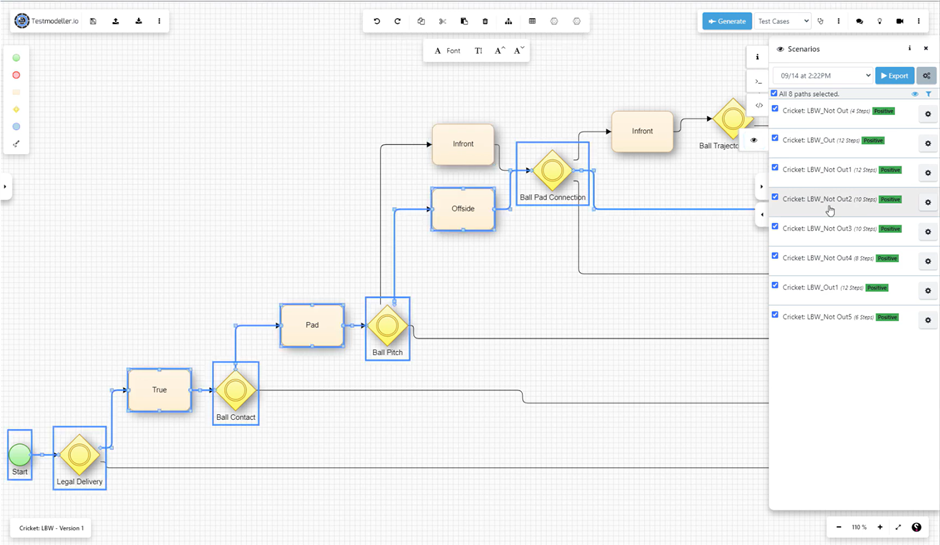
A flowchart provides a clear representation of the “LBW” rule in cricket, auto-generating paths (“tests”) through the logic.
Let’s look at the same business rules contained in our prompts earlier, representing them as models to generate data.
1. Credit Card Application
Let's look at a model for the credit card application process (Prompt 1 above). It’s much simpler to comprehend a visual model than to parse a text-based description of the same business logic:
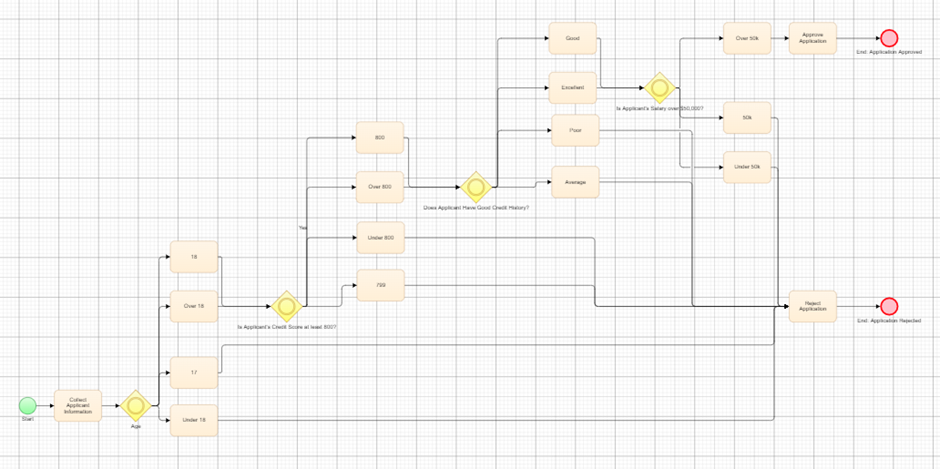
This is one of the key benefits of visualisation: it offers a more immediate, understandable depiction of the process. This has immense collaborative value, as subject matter experts can quickly assess the model for completeness, as opposed to the opaque nature of large language models (LLMs).
Within our model, we’ve recognized various equivalence classes and linked them to relevant decision points. Take, for example, the age criterion: we’ve identified several categories like over 18, exactly 18, exactly 17, and under 18. This modelling process results in the generation of a rich dataset that can be used for testing.
The model acts as a tangible representation of our business logic. Depending on the path taken through the model, a credit card application ends up either accepted or rejected. This methodical, visual approach provides us with a greater level of control and predictability than the unpredictable nature of LLMs.
Once we’ve established a model, we can use our path generation algorithm to create potential scenarios from it:
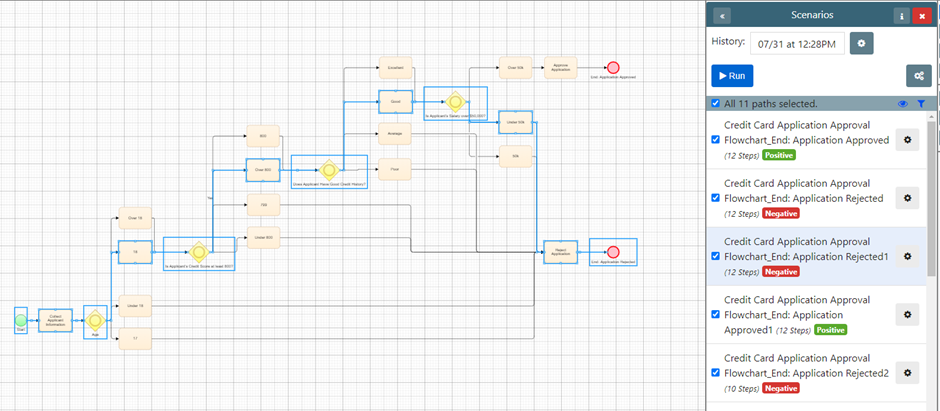
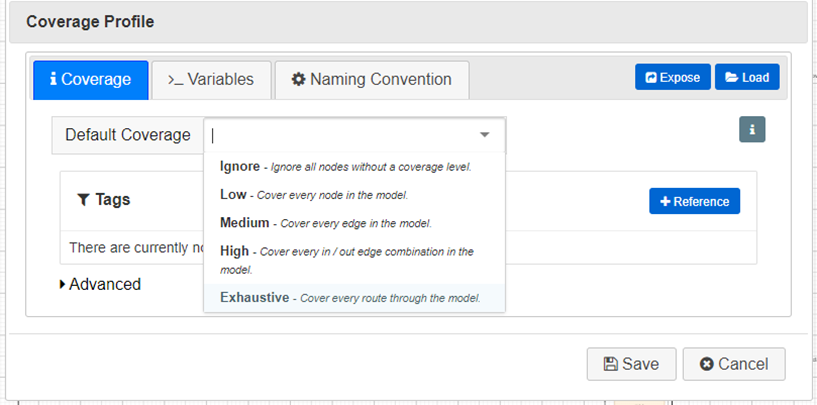
This is where the concept of coverage comes into play. Depending on your needs, you can choose from various levels of coverage – from exhaustive, which creates every possible route through the model, to simpler options like node coverage, which ensures that every decision point in the model is visited.
One of the unique aspects of our algorithm is that it gives you control over how these paths are generated. For instance, with tagging, you can specify certain scenarios to be expanded upon or focused on. This flexibility allows you to be highly specific about the scenarios you want your test data to cover. It provides a level of precision and control that simply can’t be achieved with random data generation methods:
In the example above, we’ve opted for a node coverage level. This choice has resulted in 11 unique paths, each representing a different data scenario that aligns with the embedded business rules.
These generated paths can easily be exported into various formats such as Excel, message formats, or even directly into an external database. This flexibility not only supports a wide range of testing environments, but also simplifies the process of integrating the generated test data into your existing workflow.
2. Money Transfer
Let’s explore another illustrative example: the money transfer model (Prompt 2 above):
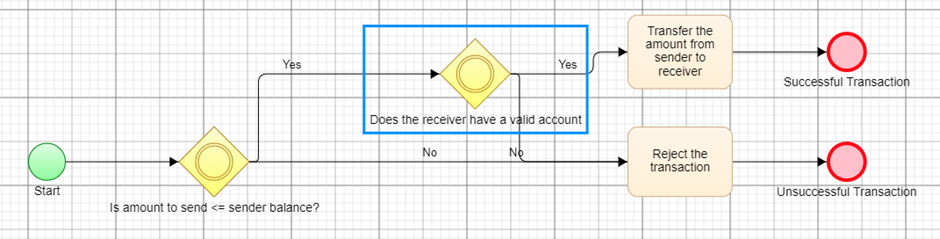
This model represents the various scenarios involved in money transfers, splitting them into two main pathways: successful and unsuccessful transactions. It’s crucial to note that a successful transfer depends on the sender having sufficient funds to cover the transfer.
This model doesn't merely outline potential outcomes; it also specifies the conditions that lead to those outcomes. It's not just about success or failure of transfers, but the specific situations that lead to those results. This leads to a wealth of test data, reflective of real-world scenarios, that we can use to ensure our system behaves as expected under different conditions.
3. E-Commerce Returns
Let's dig into a more intricate example: the e-commerce returns model (Prompt 3 above):
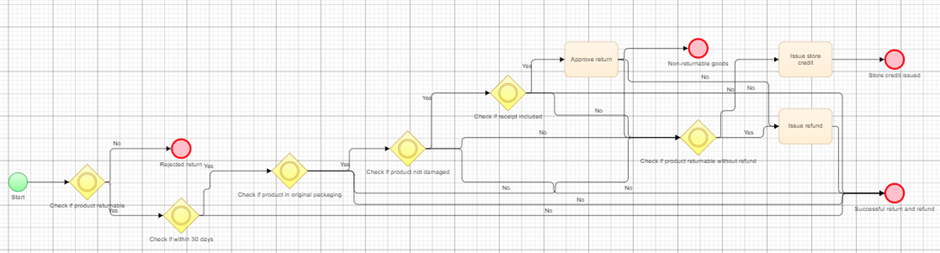
This model governs the nuanced set of conditions necessary for product returns in an e-commerce environment. The return process depends on several conditions: the item's returnability, the return request being made within 30 days of purchase, the item being in its original packaging, the product's undamaged state, and the inclusion of the purchase receipt.
This model, with its multi-layered business rules, provides a rich array of test data that encapsulates various return scenarios. By simulating all possible outcomes - from successful returns to failed attempts - we can rigorously test the systems handling these processes, ensuring their readiness for any potential real-world scenario.
Building an enterprise test data strategy
When it comes to devising an effective test data strategy, it's important to understand that using tools like ChatGPT for test data generation is not a strategy in itself. While these tools can offer a diverse set of data, they fall short in terms of data coverage and consistency with business rules.
Moreover, tools like ChatGPT do not address other crucial aspects of test data management, such as data privacy, infrastructure costs, referential integrity, and the speed of delivering data into the right data targets.
Model-Based Testing (MBT), as demonstrated in this article, offers a more systematic approach to test data generation, ensuring comprehensive coverage of business rules. However, MBT is just one piece of the puzzle. An effective test data strategy requires more than just the generation of test data.
This is where comprehensive test data management tools, like those provided by Curiosity, come into play. We offer an enterprise-level solution that addresses all aspects of test data management, giving you the control, you need to ensure high-quality testing:
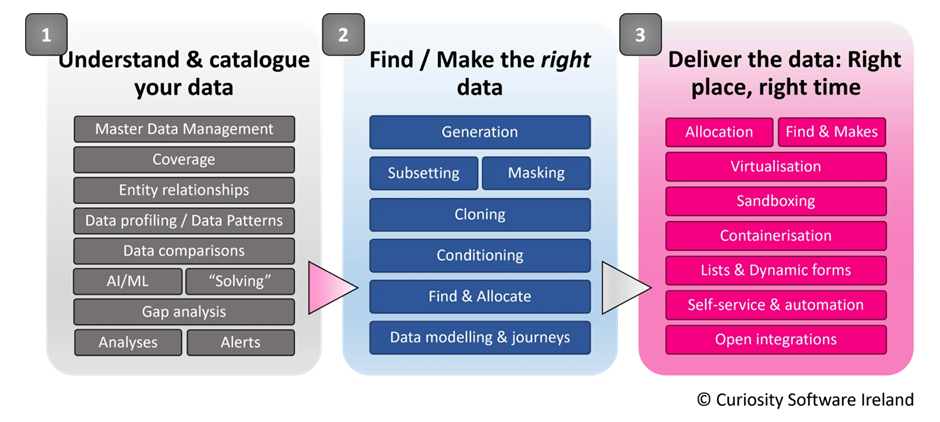
Our suite of tools includes capabilities for data masking, ensuring that sensitive information is protected while still preserving the usability of the data for testing. We offer data subsetting capabilities, allowing you to create smaller, more manageable datasets that are still representative of your larger database.
Our synthetic data generation tool ensures that you have access to high-quality test data that adheres to your business rules. In addition, we provide data profiling capabilities, which help you understand the characteristics and quality of your data. We also provide a data dictionary, ensuring that there's a clear understanding of what each data element represents.
In conclusion, while AI models like ChatGPT can offer diverse data generation, they cannot replace a comprehensive test data strategy that ensures the coverage of business rules and addresses all aspects of test data management.
At Curiosity, we're committed to providing tools that not only meet these needs but also facilitate more efficient and effective testing, driving quality across your software development lifecycle. To learn more, book a meeting with one of our test data experts.





